字符数组与字符串¶
Copyright
本页面贡献者:水之幡米拉。 本页面内容遵循 MIT 协议,转载请附上原文出处链接和本声明。
内容¶
- 计算机如何储存变量
- char数组与string
计算机是如何储存数字的¶
用二进制存储数字¶
因为计算机的构造原理,计算机只能储存0,1这两种状态(低电位代表0,高电位代表1)
那么如何表示一个我们日常生活中的数呢?这就要用到二进制
假如一段二进制数为 1010,那么它转化为10进制就是
0 * 2^0 + 1 * 2^1 + 0 * 2^2 + 1 * 2^3= 10
内存单元¶
每一个0/1数字占一位,而一个内存单元有8位,称为字节,即bit,它的单位是byte。 所以,理论上1 byte能表示的最大数是(11111111)_{(2)} =\sum_{i=0}^{7}2^i =2^8 - 1
C++中的变量¶
C++中 int 类型的变量占用四个字节,也就是有32个0/1位
那么理论上它能表示的最大的数应该是2^{32}-1
但是!!
问题在于,它该怎么表示负数?
为了表示负数,C++中把int的最高位,即代表2^{31}的那一位作为符号位,如果它是0,那就是正数,如果它是1,那就是负数,所以它可以表示 [-(2^{31}-1),2^{31}-1]
同样的,long long是8个字节,它的最高位也是表示正负,所以它可以表示 [-(2^{63}-1), 2^{63}-1]
所以说,在爆int的时候,有时候结果就会变成负数
unsigned 类型变量¶
使用unsigned int/unsigned long long时,它就将所有0/1位都用来表示数值,所以它无法表示负数,但是表示范围扩大了。
且发生算术溢出时,就相当于自动对最高位取模。
比如unsigned int ,发生溢出时,高于最高位的所有数被丢弃,就相当于对2^{31}取模。
计算机如何储存字符¶
我们可以用二进制来表示数字,但是该如何去表示字母呢?
字母与数字可以说是完全没有关系,所以肯定无法某些运算来得到
所以为了解决这个问题,大家规定,用特定数值来表示某个字母
即,建立数值与字母一一对应关系。
比如说,用65表示A,用66表示B。
ASCLL码¶
因为用特定数值表示特定字母这种方式是人为规定的,不同地区会有不同的规定,所以为了防止混乱,现在一般采用ASCII码这种对应规则。
美国信息交换标准代码是由美国国家标准学会(American National Standard Institute , ANSI )制定的,是一种标准的单字节字符编码方案,用于基于文本的数据。它最初是美国国家标准,供不同计算机在相互通信时用作共同遵守的西文字符编码标准,后来它被国际标准化组织(International Organization for Standardization, ISO)定为国际标准,称为ISO 646标准。适用于所有拉丁文字字母。
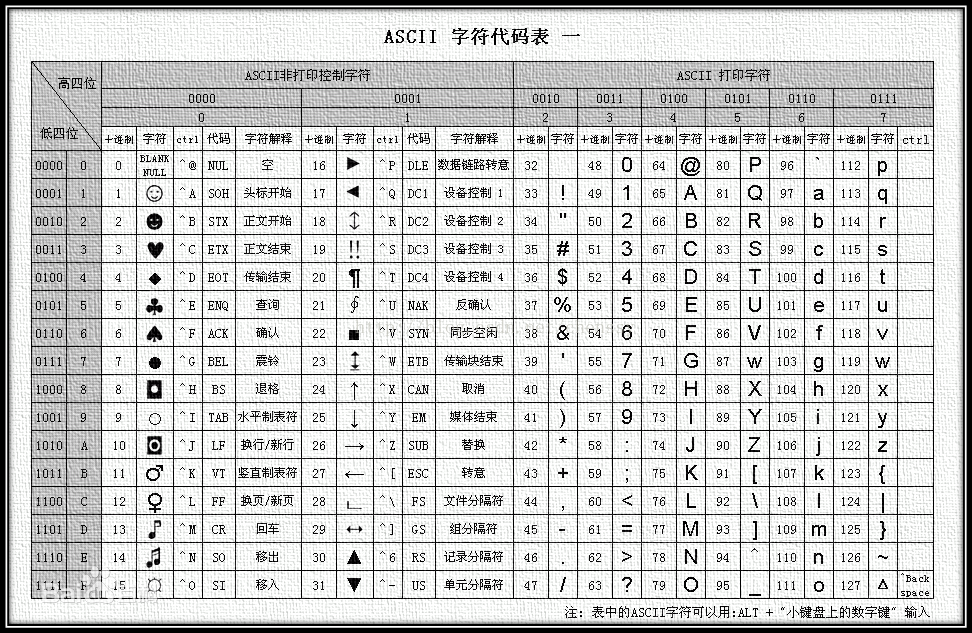
我们发现,大写字母、小写字母、数字的ASCII码是分别连续的。
即, A的ASCII码下一位就是B,c的ASCLL码下一位就是d。
具体应用¶
我们可以尝试以下程序
1 | |
那么具体发生了什么?
- %d是告诉计算机,接下来要输出的内容,是按照int类型来输出的,所以,计算机会把65对应的值,也就是65本身,输出。
- %c是告诉计算机,接下来要输出的内容,是按照char类型来输出的,所以,计算机会把65作为ASCII码,来输出其对应的字符,也就是‘A’,输出。
1 | |
%d是把'A'的ASCII码输出,%c就是输出'A'本身 因为'A'本身在内存中储存形式,其实就是数值,即65,只是根据输出方式不同,而采取不同的表现形式。
1 2 3 4 | |
1 2 3 | |
转义符¶
假如我们想让计算机输出一个空格,或者换行,怎么实现?又或者说,空格和换行,在计算机中是怎么保存的?
这就用到了转义符,在C++中,它是'\'。
比如: * 空格: '\0' * 换行符'\n'
当读入到'\'时,计算机就不会输出'\'了,而是会再读取它后面一位,以此来确定内容。
那么怎么输出一个'\'?
1 | |
字符数组¶
如果我们需要储存一串字符的话,比如'ldstql',那么我们就需要使用字符数组。
定义¶
1 | |
读入¶
1 | |
输出¶
1 | |
读入¶
1 | |
顺带一提,当你建立一个char数组时,它的每一位默认为是'\0'。
当我们用上述方法读入字符串'ldstql'时,得到的结果就是
1 2 | |
那么假如我习惯数组下标是从1开始的,怎么样才能读入的时候,s[1]开始赋值呢?
很简单,只需要在数组名后加上你想要从第几位开始的数字即可。
1 | |
1 2 | |
输出¶
输出整个字符串¶
1 | |
注意!!!! 上述规则意味着,当你读入时,如果是从第一位读入的话,那么输出的时候,也要从第一位开始,因为第0位是空格,即'\0',所以假如还是从第0位输出的话,那么它什么都不会输出。
1 | |
字符串中单个字符¶
s[i]可以访问字符串中第i个字符,此时可以把它当作字符处理。
1 | |
1 | |
cstring库¶
C++中有一个专门用来帮助我们处理字符串的库,它就叫1#include<cstring>
注意
当你使用库中内容时,必须要include
strlen()¶
strlen()这个函数,会返回给定的字符串的长度
1 | |
1 | |
我们以后读入了一个字符串,就可以用这个函数来快速获取它的长度了。
1 2 3 4 | |
strcpy()¶
strcpy(x, y)的作用是把y字符串拷贝给x
1 2 3 | |
1 2 3 4 | |
string¶
cstring为我们提供了一个类(现在可以认为是个又特殊功能的变量),叫做 string,它本身就是一个字符串。
声明¶
1 | |
读入¶
1 | |
string其余部分,与char数组一致。
1 2 | |
string还自带很多功能。
1 2 3 4 | |
两个string类型之间可以直接相加,相当于把后面string的加到前面string的后面。
1 2 | |
但是,string类型之间是没有减法运算的 : (
一些细节¶
不管是string,还是char数组,当你对整个数组进行读入时,会直接覆盖掉之前的所有字符,哪怕之前字符串长度是114514,你对整个字符串输入了一个字符串,那就会清除掉之前所有的字符。但如果你对单个位置进行读入,那么是不会覆盖掉其余部分的。
1 2 3 4 5 6 7 8 9 10 | |
string数组¶
string 也是可以开成数组形式的。
1 2 3 4 5 6 | |
例题 判断回文串¶
给定一个由小写英文字母组成的字符串,判断它是否为回文串。
回文串的定义为:这个字符串从左往右读和从右往左着读是一样的,比如'cucuc'是回文串,而'niconiconi'就不是回文串。
提示¶
对于一个字符串,假如它的长度为n,我们从第1位开始读入,那么我们怎么知道与它对应的字符呢?
比如第i位,与之对应的就是n - i + 1
1 2 3 4 5 6 7 | |